# 《Python绝技——虫术》
这本书讲的内容非常完整和全面,Scrapy源码和生产中用到的部署和分布式、反爬和具体案例,值得深入实践之后多看几遍。虽然很多资料是网上公开收集到的,不过作者也有一些自己的理解。
阅读时间:2020年8月27日 4小时6分
# 第1章:爬虫初步
介绍爬虫分类和BeautifuSoup实例。
# 第2章: Scrapy基础知识
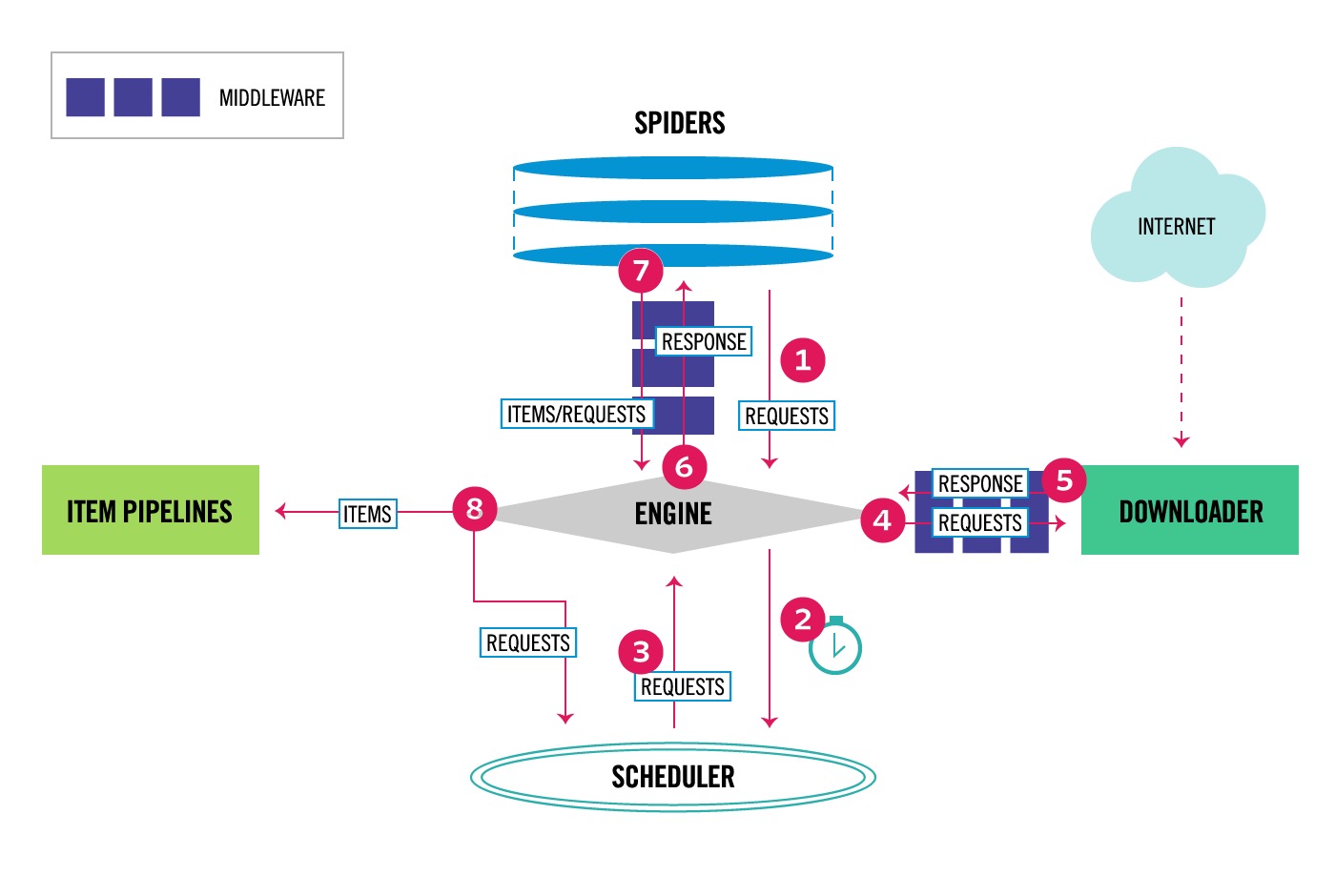
Scrapy中的数据流过程:
- 引擎打开一个网站,找到处理该网站的Spider并向该Spider请求第一个要爬取的URL(s).
- 引擎从Spider中获取第一个要爬取的URL并在调度器(Scheduler)中以Request调度
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(Response)方向)发给引擎。
- 引擎从下载器中接收Response并通过Spider中间件(输入方向)发给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第2步)重复直到调度器中没有更多的Request,引擎关闭对该网站的执行进程。
Scrapy Engine:
- 调度器(Scheduler)
- 下载器(Downloader)
- 蜘蛛(Spiders)
- 数据管道(Item Pipeline)
- 下载器中间件(Downler middlewares)
- Spider中间件(Spider middlewares)
scrapy startproject chainnes_crawler
scrapy crawl -o result.json
# -o 参数是指『输出到文件』
2
3
Field类只是简单地继承至一个字典类(dict)。同样,Item是继承自DictItem这个字典类用法非常相似的类,也就是说,当Item被实例化后直接将其作为字典来使用就行了。
与return不同的是,yield返回的是一个迭代器而不是具体值,且yield不会像return直接将当前执行代码中断并返回,而是将当前可被返回的对象生成一个迭代器,然后继续执行下一行的代码。
用直接的方式来理解就是一个深层次就需要有一个parse函数产生下一层次的请求对象,当不再产生新的请求对象就意味着这种深度循环的终结。最后,当parse方法返回的是一个Item的枚举时,标志着这个蜘蛛已经完成它需要处理完的事情了,Scrapy工作流将移交到一个处理步骤中去,也就是下一节要讲述的"管道"。
Pipeline的类别:
- 清理HTML数据
- 验证爬取的数据(检查Item包含某些字段)
- 去重(并丢弃)
- 将爬取结果保存到数据库中
编写自定义管道非常简单,每个管道都是一个具有process_item方法的Python类
class MyPipeline(object):
def process_item(self, item, spider):
return item
2
3
每个管道都需要调用process_item方法,而且这个方法必须返回一个Item对象或是抛出一个DropItem异常。以下是process_item方法的参数说明:
- item——当前处理的Item对象
- spider——产生当前Item对象的蜘蛛实例
ITEM_PIPELINE内要以全路径引用管道类,可以同时指定多个管道(以逗号分隔)。在":"后紧跟着的数字表示优先级(表示其执行的顺序),数字越小优先级越高。通常这些数字的取值范围在0~1000之内。
# 第3章:Scrapy的工程管理
开发与测试环境都基于Scrapy,开发环境中以scrapyd-client作为自动化部署工具,而生产环境中将以Scrapyd工具为宿主,向外部提供生产环境的管理接口。
我们可以以手工方式将文件上传到服务器,但最简单的办法是通过scrapyd-deploy软件工具包中附带的scrapyd-client客户端来完成这一项工作。
Scrapyd提供的RESTful API的一览表:
- daemonstatus.json:GET 检查Scrapyd的运行状态
- addversion.json:POST 向Scrapyd增加一个项目版本,如果项目不存在,则自动创建一个新的项目
- schedule.json:POST 加载运行指定的蜘蛛
- cancel.json: POST 终止蜘蛛的作业
- Listprojects.json: GET 获取当前的Scrapy服务器中所有的已上传项目列表
- Listversions.json: GET 获取项目中可用的版本列表。版本会按照顺序排列,最后一个为当前正在使用的版本
- Listspiders.json: GET 获取当前版本中可用的蜘蛛列表
- Listjobs.json: GET 获取项目中待定、正在运行或者已完成的作业列表
- Delversion.json: POST 删除项目中指定的版本
- Delproject.json: POST 删除指定项目及其所有已上传的版本
Scrapyd-client的使用
# 第4章:中阶虫术
介绍通用蜘蛛:XMLFeedSpider
通过蜘蛛中间件可以实现一下操作:
- 检测蜘蛛爬网的深度
- 检测返回的HTTP响应是否有效
- 在蜘蛛执行之前自动过滤无效的请求
- 限制蜘蛛的某些行为
- 其他用于控制蜘蛛行为的处理
HTTP的头域包括通用头、请求头、响应头和实体头四个部分。
介绍正则表达式
要在Python中处理JavaScript网页有两种办法:
- Selenium + WebDriver
- Splash
PhantomJS是一个“无头”(headless)浏览器,使用著名的V8引擎构建。它会把网站加载到内存中并执行页面上的JavaScript,但不会向用户展示网页的图形界面。
介绍云存储文件
介绍数据库存储
# 第5章:高阶虫术
介绍布隆过滤器
突破反爬
代理池的使用
Scrapy-redis分布式爬取数据